Abstract
Diffusion models have proven to be highly effective in image and video generation; however, they still face composition challenges when generating images of varying sizes due to single-scale training data. Adapting large pre-trained diffusion models for higher resolution demands substantial computational and optimization resources, yet achieving a generation capability comparable to low-resolution models remains elusive. This paper proposes a novel self-cascade diffusion model that leverages the rich knowledge gained from a well-trained low-resolution model for rapid adaptation to higher-resolution image and video generation, employing either tuning-free or cheap upsampler tuning paradigms. Integrating a sequence of multi-scale upsampler modules, the self-cascade diffusion model can efficiently adapt to a higher resolution, preserving the original composition and generation capabilities. We further propose a pivot-guided noise re-schedule strategy to speed up the inference process and improve local structural details. Compared to full fine-tuning, our approach achieves a $5\times$ training speed-up and requires only an additional 0.002M tuning parameters. Extensive experiments demonstrate that our approach can quickly adapt to higher resolution image and video synthesis by fine-tuning for just 10k steps, with virtually no additional inference time.
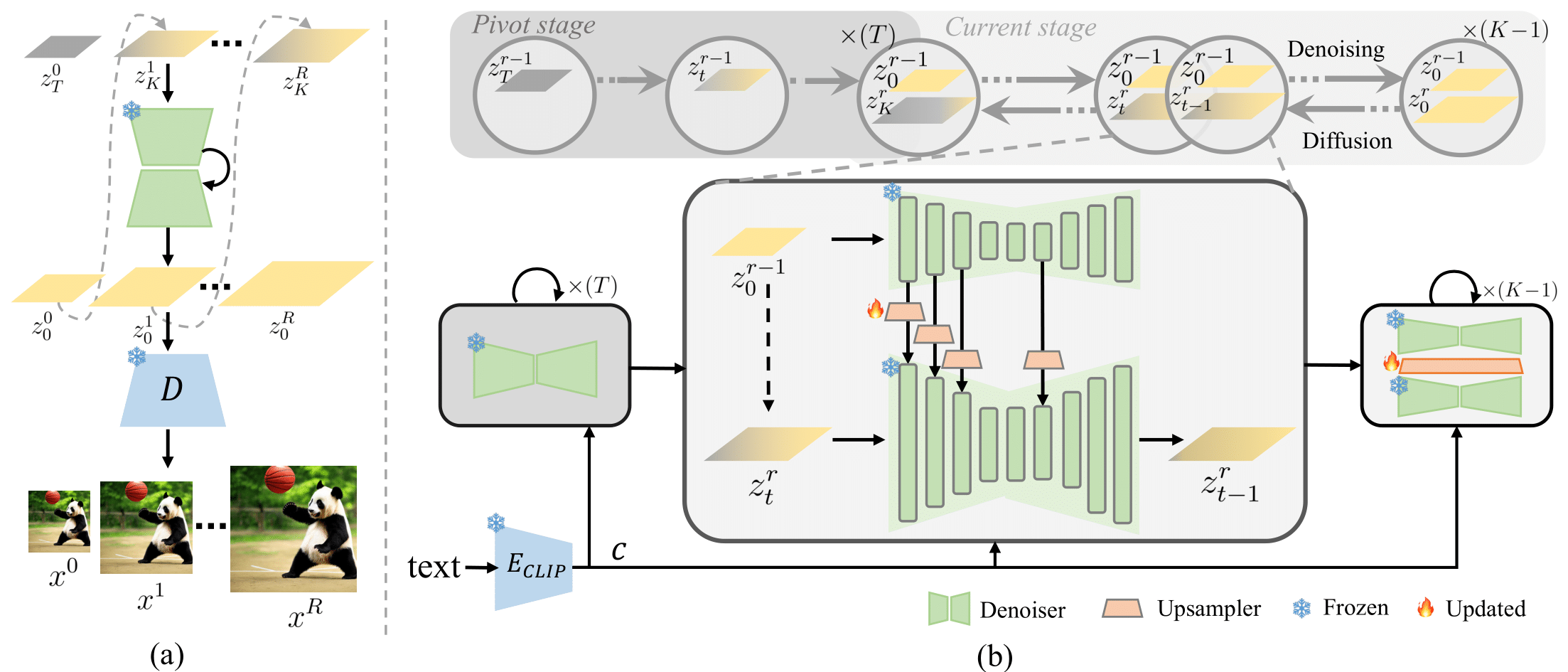
Self-Cascade Diffusion Model
Text to Image
Samples with 2048*2048 generated by SD 2.1 training with 512*512.

"Oil painting of a fox in the cornfield."

"As I turned the pages, a magnificent tree sprouted from the book, its branches laden with ripe fruit that fell to the floor, filling the room with a sweet, intoxicating aroma, highly detailed, 8k."

"A photo of a Corgi dog wearing sunglasses skateboarding in Times Square."

"“A tiger walks in a snowy winter in country road."

“Maine Coon.”

"The winding Great Wall of China in autumn."

"A photo of a city skyline at night."
Samples with 1024*1024 generated by SD 2.1 training with 512*512.
| Attn-SF([5]) | ScaleCrafter([5]) | Ours-TF | ||
|---|---|---|---|---|

|

|

|
Full Fine-Tuning | LORA Rank-4 | Ours-T |

|

|

|
||
|
"An AI art piece that highlights the excitement of a turbo boost, with Mario's kart emitting flames and sparks as he accelerates." |
||||
| Attn-SF([5]) | ScaleCrafter([5]) | Ours-TF | ||
|---|---|---|---|---|

| 
| 
|
Full Fine-Tuning | LORA Rank-4 | Ours-T |

| 
| 
|
||
|
"A ginger cat is eating doughnut." |
||||
| Attn-SF([5]) | ScaleCrafter([5]) | Ours-TF | ||
|---|---|---|---|---|

| 
| 
|
Full Fine-Tuning | LORA Rank-4 | Ours-T |

| 
| 
|
||
|
"A retro poster of a post apocalyptic dystopian universe, of a mustang style muscle car, extreme color scheme, mad max themed, driving speeding on a desert road, fleeting from being chased by an aggressive giant fire breathing dragon, in action shot, highly detailed digital art." |
||||






Samples with 4096*4096 generated by SD XL training with 1024*1024.

“Soft pink roses, white Chinese peony, tiny apple blossom flowers, eucalyptus leaves, twigs of cranberries, twigs of copper pepper berries all arrangement into a cute beautiful flowers arrangement on a pink nickel mug. The mug is sitting on a thick white book with golden cover image design. Sunny, bright image. Ad copy, huge copy space on top of the image, negative space, hd, 8k, blurry dreamy background, beautiful pictures. ”

“An ostrich walking in the desert, photorealistic, 4k."

"Realistic Giraffe snail."

“A painting of a fish on a black background, a digital painting, by Jason Benjamin, shutterstock, colorful vector illustration, mixed media style illustration, epic full color illustration, mascot illustration. ”

"A cute little matte low poly isometric cherry blossom forest island, waterfalls, lighting, soft shadows, trending on Artstation, 3d render, monument valley, fez video game. "

"A small cactus with a happy face in the Sahara desert. "

"A woman in a pink dress walking down a street, cyberpunk art, inspired by Victor Mosquera, conceptual art, style of raymond swanland, yume nikki, restrained, robot girl, ghost in the shell. "

"(fractal crystal skin:1.1) with( ice crown:1.4) woman, white crystal skin, (fantasy:1.3), (Anna Dittmann:1.3)."

“Isometric style farmhouse from RPG game, unreal engine, vibrant, beautiful, crisp, detailed, ultra detailed, intricate.”

“Chinese architecture, ancient style,mountain, bird, lotus, pond, big tree,(thick paint style:1.3), (wide angle lens:1.4), (best lighting), 4K Unity, (super-detailed CG: 1.2) , (8K: 1.2), octane rendering.”

"Ethereal fantasy concept art of thunder god with hammer. magnificent, celestial, ethereal, painterly, epic, majestic, magical, fantasy art, cover art, dreamy." "

"Create a Van Gogh style starring Sky with Thoughtful John Wick , painting, photo."

"(Ultrarealistic:1.3), (Award Winning Photo:1.3), a man stands near a massive lonely magic (glowing tree:1.3) in the middle of the snow field, (branches radiated a soft warm glow:1.3), full moon, winter night, deep snow everywhere, (otherworldly glow:1.2), (on a background of starry night:1.3), masterpiece, (realism:1.2), high contrast, (photorealism digital art:1.3), Intricate, 8k HD high definition detailed, HDR, hyper detailed, best quality."

"Steampunk makeup, in the style of vray tracing, colorful impasto, uhd image, indonesian art, fine feather details with bright red and yellow and green and pink and orange colours, intricate patterns and details, dark cyan and amber makeup. Rich colourful plumes. Victorian style."

"A traveler navigating via a boat in countless mountains, Chinese ink painting."

"A marble statue of a Koala DJ in front of a marble statue of a turntable. The Koala has wearing large marble headphones.""

"A teddy bear is riding bike, high details."
Text to Video
Samples with 512*512 generated by SD 2.1 training with 256*256.
| Full-FT (50k) | LORA-R32 (50k) | Ours (10k) | ||
|---|---|---|---|---|
| > | > | > | ||
|
"Old man walking in the moorland valley, snowing heavily." |
||||
| > | > | > | ||
|
"A playful kitten bats a ball of yarn with its paw." |
||||
| Full-FT (50k) | LORA-R32 (50k) | Ours (10k) | ||
|---|---|---|---|---|
| > | > | > | ||
|
"A vibrant hummingbird tirelessly flits between flowers, drinking sweet nectar." |
||||
| > | > | > | ||
|
"A panda contentedly munches on bamboo leaves, enjoying a tranquil afternoon." |
||||
| Full-FT (50k) | LORA-R32 (50k) | Ours (10k) | ||
|---|---|---|---|---|
| > | > | > | ||
|
"A colorful parrot mimics the voices it hears, much to its human companion's amusement." |
||||
| > | > | > | ||
|
"A charming raccoon stealthily rummages through a homeowner's trash can." |
||||
| Full-FT (50k) | LORA-R32 (50k) | Ours (10k) | ||
|---|---|---|---|---|
| > | > | > | ||
|
“A graceful swan glides across a serene pond, exerting minimal effort.” |
||||
| > | > | > | ||
|
“A peacock is walking proudly through the garden.” |
||||
| Full-FT (50k) | LORA-R32 (50k) | Ours (10k) | ||
|---|---|---|---|---|
| > | > | > | ||
|
“A young couple walking in a heavy rain.” |
||||
| > | > | > | ||
|
“Horse drinking water.” |
||||
BibTeX
@article{guo2024make,
title={Make a Cheap Scaling: A Self-Cascade Diffusion Model for Higher-Resolution Adaptation},
author={Guo, Lanqing and He, Yingqing and Chen, Haoxin and Xia, Menghan and Cun, Xiaodong and Wang, Yufei and Huang, Siyu and Zhang, Yong and Wang, Xintao and Chen, Qifeng and others},
journal={arXiv preprint arXiv:2402.10491},
year={2024}
}